
Quadrant models are useful organizing tools. Let’s use one to look at the problem of managing the attributes of entities in systems visibility. I’m not expecting to solve the problem, just usefully describe the playing field.
Horizontal axis:
* persistent entities with changing attributes
* ephemeral entities with static attributes
Vertical axis:
* Set the relationship at index time
* Set the relationship at search time
Let’s start with the old school entities model. Once upon a time managed computers were modular, high value devices. A server or desktop would be repaired or upgraded by replacing components. If its use case went away, the device would be repurposed to another use case. It did not vanish until accounting was certain it had fully depreciated and could be sold, donated, or scrapped. This state of affairs persists at the high end, so it’s still worth considering. Someone’s racking and stacking some pricey hardware to make things go.
Top Left: Persistent entities, Index time relationships
The computer (let’s call it THESEUS) has a timeline of footprints. Business Analytics teams can see it in their Enterprise Resource Planning (ERP) systems, contract tracking, and accounting systems. Facilities knows it by its power draw and heat load. Security Operations has interest in it, and their agents come and go with the vicissitudes of fortune. Lights On Doors Open (LODO) Operations cares the most about it, and tracks it closely as it serves each purpose of its lifecycle.
Each group’s view into the computer’s function is limited by their immediate needs. Most of the time, various teams are happy with their limited view into this entity. They are able to set any needed attribute to entity mappings at index time, when data about the device is collected. Changes don’t much matter, and can be manually updated or ignored.
Bottom Left: Persistent entities, Search time relationships
This works until change spills over between groups: for instance, if a missed recall for a faulty part leads to a hardware failure that starts a fire, Facilities and LODO will be equally interested in how they could have better coordinated with Business Analytics functions. “Where was this ball dropped?” The answer is often “changes in reality were lost because we don’t keep proper track of entities.” Of course no one states it like that. Rather, they say “we received the recall and sent it to the point of contact on record.” This scenario plays out in security as well, when incident responders can’t find out if an attacked device is safe to restart, or when a monitoring tool alert is how they learn that DevOps is rolling out a new service. These misses in visibility drive folks towards mapping attributes to entities at search time. Of course, no one says it like that; they say “we’re bringing updated data into our visibility tools.”
There’s a dirty secret in those tools though. Actively mapping attributes to entities entirely at search time is a hard problem to scale, and it gets even harder to do if you want to maintain that awareness into past records as well as the present. Few systems can handle “this was SVR42 before Tuesday, now it’s SVR69”. Add in that behavior has changed and the old model is still good for old records but a new model needs to be started, and most tools give up and start a new entity record. Sorry administrators and analysts, here are the tools for pruning stale entities from the system, good luck!
Lower Right: Ephemeral entities, Search time Relationships
And so a sea change: what if that whole set of reality based problems is outsourced, and the organization uses ephemeral virtual devices based on static configurations to perform its tasks? Amazon and Microsoft still have to worry about physical hardware, but the rest of us can just inject prebuilt software bundles into a management tool and let the load balancers figure it out. As long as logging is done properly and auditing can still be supported, this can be a great answer. The unpredictable nature of this world has precipitated a tsunami of heisenbugs, but unifying development and operations reduces the lag time for diagnosing those. Furthermore, the attribute to entity relationship really doesn’t matter; who cares what address or hostname a function was served from? All that matters is service level objectives and agreements: success, failure, completion time, and resource consumption. It’s a pretty ideal solution for anything where the entity is disposable: simply stop tracking it at all, and use temporary search time relationships based on the functions that were served to maintain visibility.
Upper Right: Ephemeral entities, Index time relationships
Although… that requires the analyst to know what they need to track up front. If the image doesn’t issue enough data attributes to answer a question, you’re out of luck. That’s annoying for internal visibility, but the internal folks aren’t the only ones asking questions. A hypothetical: there was an instance on Tuesday, let’s call it EPHEMERIDES. Interpol would like to know what it was doing at 10 AM UTC because it was apparently exploited and used for evil deeds. Or maybe not? Who knows? In the long-lived server world, we would have been dumping all output into a central system and could sort through it on demand, but now we just know that it was doing its intended job within acceptable parameters. That’s all we’d decided to monitor. If we’re not proactively tracking the organization’s activities from its infrastructure, we’ll have to track something else to achieve visibility. Why bother? Well, let’s talk about how you’re going to prove compliance with data privacy regulations or due diligence security assurances when you can’t say what happened where last Tuesday. “Trust us, we’re pretty sure it didn’t do anything bad in the few hours it was alive” may not wash in court. An easy solution is to dump whatever you can from these devices into the cheapest storage possible, with some index-time identifiers to make it hopefully retrievable later. And if that’s not possible? Oh well, at least we tried and the fines will probably be reduced.
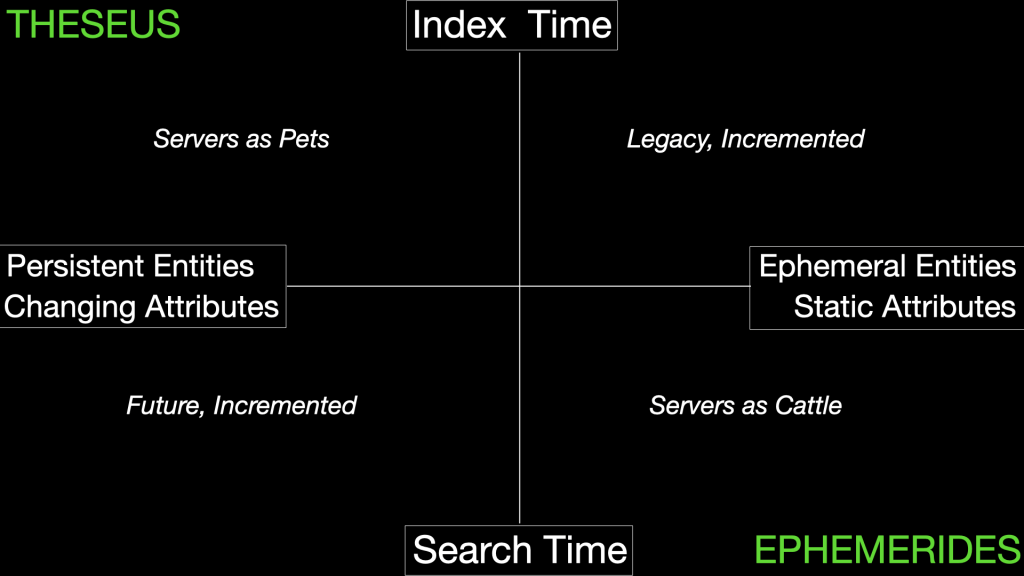
- Top left is the legacy, revolution against the mainframe. It’s servers as pets, deploy then configure thinking.
- Bottom left, legacy incremented, insufficiently.
- Bottom right is the future, servers as cattle, configure then deploy thinking. Revolution against the Wintel and Lintel server world, of course.
- Top right, the future incremented, insufficiently.
Hopefully this has been fun and useful!

